Искусственный Интеллект в вашей серверной - оборудование для локального запуска AI моделей
Мы даем возможность использовать большие языковые и визуальные модели (LLM и VLM), запуская их на наших рабочих станциях и серверах у вас в офисе.

Серверы для ИИ

Мы производим серверы для Искусственного Интеллекта на базе модифицировнных ГПУ карт потребительского класса RTX4090/5090 с удвоенной vRAM, измененной схемотехникой, пониженной частотой памяти и ядра, и улучшенным охлаждением, позволяющие разворачивать полноразмерный локальный ИИ.
Разработка ИИ продуктов

Наши разработчики предоставляют услуги по установке и оптимизации локальных ИИ моделей, разработке прототипов и полноценных корпоративных решений на базе искусственного интеллекта для бизнеса.
Доступный облачный ИИ

Мы предоставляем облачную инфраструктуру на базе серверов и графических карт нашего производства - вы получаете вычислительную мощность корпоративных ИИ решений (A100/H100) по цене потребительских.

Наши решения для вас, если…
Линейка ИИ решений

Пониженная частота ядра и памяти дают стабильность и низкую рабочую температуру. Удвоенная с 24Gb до 48Gb память обеспечивает стабильную работу тяжелых версий моделей Deepseek R1, Qwen 2.5

ИИ Станция - 4 x RTX4090M GPU станция, для моделей до 180Gb
Рабочая станция, позволяющий размещать 4 карты RTX4090M и дающая производительность 1.4 карт Nvidia A100 за счет расширенной vRAM (96Gb на две карты и технологии GPU-direct)

x8 GPU Сервер, с общим объемом vRAM до 384Gb
Эффективное воздушное охлаждение стека из 12 вентиляторов, размещенных посередине корпуса позволяет картам работать не перегреваясь.

x20 GPU Сервер, с общим объемом vRAM до 960Gb
Решение позволяет получить производительность блока H20 на базе карт RTX4090M и производить fine-tuning моделей на 100 млрд и более параметров в разрешении FP16

Enterprise-grade Сервер с поддержкой модулей H100, H20 Nvlink
Сервер позволяет использовать блоки AI карт H100, H20 с поддержкой Nvlink и подходит для обучения базовых (foundational) моделей

Кастомизированные решения под требования ЦОД
На базе наших платформ мы можем производить полностью кастомизированные решения для ЦОД, под требования заказчика
НАШИ ПРОДУКТЫ
Сервер на x20 GPU потребительского класса (RTX family)
Fine-tuning, и использование моделей на 100 млрд параметров и более в FP16
Сервер на для AI карт H100 и H20 NVLINK
Максимально возможная скорость передачи данных для обучения базовых моделей
Наши преимущества

В основе наших AI решений лежат модифицированные GPU семейства RTX
В GPU удвоена память vRAM, переработано охлаждение и снижена частота ядра и памяти, что обеспечивает более высокую производительность в ИИ задачах при высокой стабильности и отсутствии ошибок.
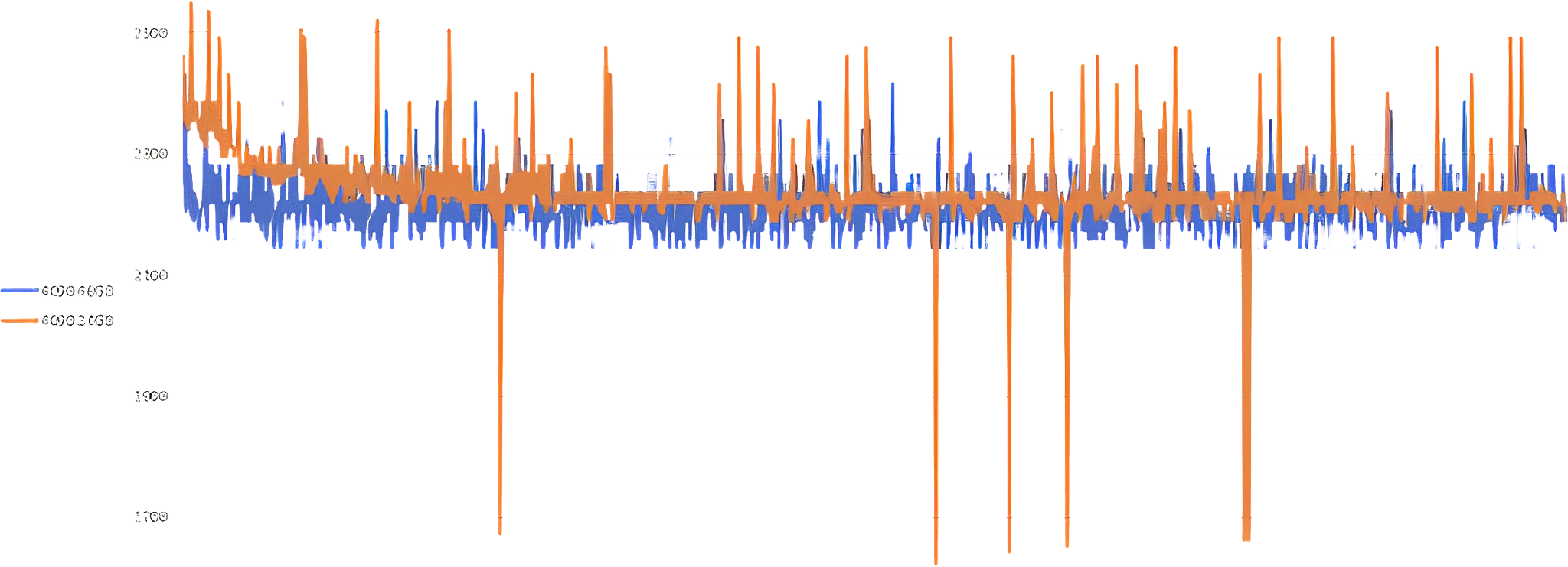
Стабильность частоты ядра модифицированной RTX4090M 48Gb в сравнении с RTX4090 24Gb (оранжевый)
Стабильность достигается за счет замены базового вентилятора карты и понижения частот ядра и памяти.
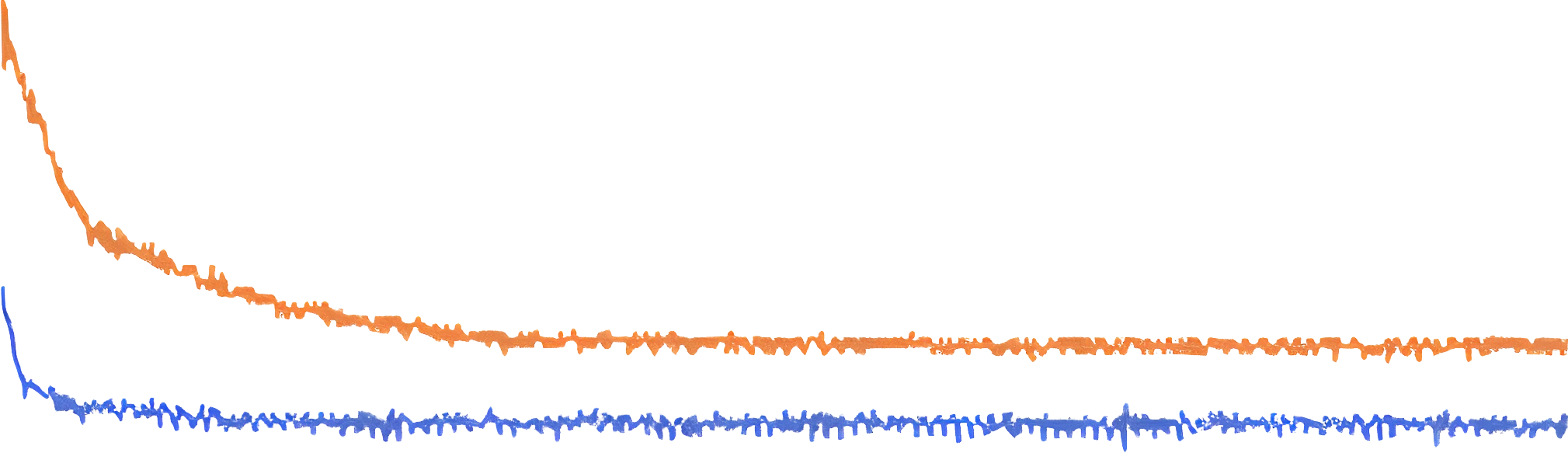
RTX4090M 48Gb на 2.5% мощнее в LLM и на 3.6% слабее в CNN задачах в сравнении со стандартной RTX4090 24Gb
Производительность RTX4090M - 130000 Gflops, производительность RTX4090 24Gb - 132000 Gflops.
Скачать отчеты о производительности

Наше производство находится в Китае, городе Шэнчжэнь. Мощность производства 50.000 серверных платформ в год. При необходимости мы используем линии нашего партнера Foxconn.
Производство основано в 2010 инженерной командой DELL с целью выпуска кастомизированных серверных решений для ЦОД. За 15 лет были разработаны решения, покрывающие всю линейку процессоров Intel и AMD, от одноюнитовых серверов для простых вычислений до тяжелых многопроцессорных решений.
Команда RnD составляет 60+ инженеров, более 100 запатентованных технологий и широкая сеть партнеров в технологическом секторе Китая. Нашими клиентами являются как крупные китайские компании с фокусом на ИИ (Insta360, HiteVision, Hillstone), так и крупные Российские потребители в банковском, телеком и индустриальном секторах.
Отзывы пользователей наших продуктов

Банки

ЦОДы
